LLaVA-OneVision是什么
LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。
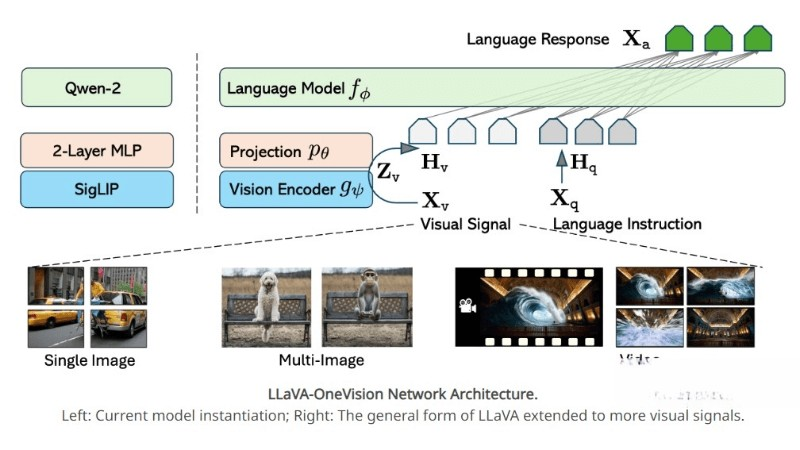
LLaVA-OneVision的主要功能
- 多模态理解:能理解和处理单图像、多图像和视频内容,提供深入的视觉分析。
- 任务迁移:支持不同视觉任务之间的迁移学习,尤其是图像到视频的任务迁移,展现出视频理解能力。
- 跨场景能力:在不同的视觉场景中展现出强大的适应性和性能,包括但不限于图像分类、识别和描述生成。
- 开源贡献:模型的开源性质为社区提供了代码库、预训练权重和多模态指令数据,促进了研究和应用开发。
- 高性能:在多个基准测试中超越了现有模型,显示出卓越的性能和泛化能力。
LLaVA-OneVision的技术原理
- 多模态架构:模型采用多模态架构,将视觉信息和语言信息融合,以理解和处理不同类型的数据。
- 语言模型集成:选用了Qwen-2作为语言模型,模型具备强大的语言理解和生成能力,能准确理解用户输入并生成高质量文本。
- 视觉编码器:使用Siglip作为视觉编码器,在图像和视频特征提取方面表现出色,能捕捉关键信息。
- 特征映射:通过多层感知机(MLP)将视觉特征映射到语言嵌入空间,形成视觉标记,为多模态融合提供桥梁。
- 任务迁移学习:允许在不同模态或场景之间进行任务迁移,通过这种迁移学习,模型能发展出新的能力和应用。
LLaVA-OneVision的项目地址
- GitHub仓库:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
- arXiv技术论文:https://arxiv.org/pdf/2408.03326
如何使用LLaVA-OneVision
- 环境准备:确保有合适的计算环境,包括硬件资源和必要的软件依赖。
- 获取模型:访问LLaVA-OneVision的Github仓库,下载或克隆模型的代码库和预训练权重。
- 安装依赖:根据项目文档安装所需的依赖库,如深度学习框架(例如PyTorch或TensorFlow)和其他相关库。
- 数据准备:准备或获取想要模型处理的数据,可能包括图像、视频或多模态数据,并按照模型要求格式化数据。
- 模型配置:根据具体应用场景配置模型参数,涉及到调整模型的输入输出格式、学习率等超参数。
LLaVA-OneVision的应用场景
- 图像和视频分析:对图像和视频内容进行深入分析,包括物体识别、场景理解、图像描述生成等。
- 内容创作辅助:为艺术家和创作者提供灵感和素材,帮助创作图像、视频等多媒体内容。
- 聊天机器人:作为聊天机器人,与用户进行自然流畅的对话,提供信息查询、娱乐交流等服务。
- 教育和培训:在教育领域,辅助教学过程,提供视觉辅助材料,增强学习体验。
- 安全监控:在安全领域,分析监控视频,识别异常行为或事件,提高安全监控的效率。
© 版权声明
本站文章版权归AI365导航网所有,未经允许禁止任何形式的转载。
相关文章




















AI365导航网收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,AI365导航网还推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。